 V miniseriálu o funkcionálním programování jsem se zabýval zpracováním CSV souboru. Soubor, tedy textový dokument, jakým je CSV, můžeme v zásadě zpracovávat dvěma způsoby: vše načíst do paměti a nebo využít stream.
V miniseriálu o funkcionálním programování jsem se zabýval zpracováním CSV souboru. Soubor, tedy textový dokument, jakým je CSV, můžeme v zásadě zpracovávat dvěma způsoby: vše načíst do paměti a nebo využít stream.
Tedy buď:
var lines = File.ReadAllLines(fileName);
foreach (var line in lines)
{
...
a nebo
using (var reader = new StreamReader(fileName))
{
while ((line = reader.ReadLine()) != null)
{
...
Pro ReadAllLines:
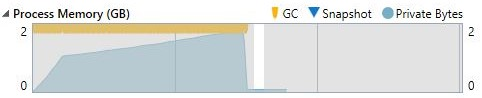
a nebo
using (var reader = new StreamReader(fileName))
{
while ((line = reader.ReadLine()) != null)
{
...
Každý z těchto přístupů má své pro a proti a rozdíly vyniknou zejména při zpracování velkých souborů, například zpracování CSV s cca jedním miliónem řádků o velikosti cca 800 MB vypadá takto:
Pro ReadAllLines:
Pro StreamReader:

Čtení po řádcích, tedy s využítím StreamReaeru, znamená citelně menší zabranou paměť, čas nutný na přečtení souboru je ale o cca 5-10% delší než pro ReadAllLines. Ovšem tam za toto zrychlení platíme pamětí, které je potřeba cca 9-krát více.
Samozřejmě že u malých, běžně zpracovávaných souborů, je to skoro jedno, ale pokud potřebujeme zpracovat delší soubor, je dobré vědět o těchto rozdílech.
I must thank you for the efforts you have put in penning this site. I am hoping to check out the same high-grade content by you later on as well. In truth, your creative writing abilities has inspired me to get my own, personal blog now..
OdpovědětVymazatUGC Approved Journals
UGC Recognized Journals
Scopus Indexed Journals
Scopus Journal List
Proof Reading
Your blog updates are good enough and impressive, expecting much more from your side:
OdpovědětVymazatBest Architects in India
Turnkey Interior Contractors in Chennai
Architecture Firms in Chennai
Warehouse Architect
Factory Architect Chennai
Office Interiors in Chennai
Rainwater Harvesting chennai